
Oguz Guerk*
Man kann nicht sagen, dass in der Türkei bis in die 1980er Jahre öffentliche Meinungsumfragen institutionell und in regelmäßigen Abständen durchgeführt wurden. Mit den Parlamentswahlen 1983 begannen die Medienorganisationen, öffentliche Meinungsumfragen finanziell zu unterstützen und diesen Untersuchungen in den Medien großen Raum einzuräumen, und öffentliche Meinungsumfragen wurden zu einem beispiellosen Teil des täglichen Lebens während der Wahlperioden und verbreiteten sich immer mehr. Andererseits gab es, soweit ich mich erinnern kann, bei früheren Wahlen in der Türkei nicht so viel Interesse an „Umfragen“ oder „Wahlsimulationen“ wie heute, die wahrscheinlich aus den USA importiert wurden, um das Wahlumfeld in der Türkei zu untersuchen ( und die Praxis des Wählens ist zunehmend ein technisches Problem.) Wir sind mit neuen „Gewohnheiten“ konfrontiert.
In diesem Artikel möchte ich die Aufmerksamkeit auf einige wertvolle Punkte zu Umfragezusammenschlüssen im Allgemeinen lenken, nicht zu Simulationen von Wahlen (oder Stellvertreterverteilungen in einer imaginären Versammlung). Bei den Präsidentschaftswahlen 2018 (CB) und den Kommunalwahlen 2019 gibt es eine Reihe von Tools, die wir anwenden können, um zu verstehen, wie ein „Genauigkeits“-Index von Unternehmen abgeleitet werden kann, die einen Monat vor der Wahl Wahlumfragen veröffentlicht haben, und wie man einen „Genauigkeitsindex“ erstellt. Poll Aggregation“ für den 14. Mai anhand dieser Informationen. Eine davon besteht darin, den Nutzen eines Index dafür zu ermitteln, wie „genau“ jedes Unternehmen im Allgemeinen ist, indem die Fehlerquoten der Unternehmen bei vergangenen Wahlen anhand eines gemeinsamen und von Wahl zu Wahl geltenden Benchmarks bewertet werden. Dabei gehen wir davon aus, dass das relative Gewicht des Unternehmens, das die Umfrage durchführt, bei der Fusion umso höher sein sollte, je mehr die letzte von einem zufälligen Unternehmen vor einer Wahl durchgeführte Umfrage mit dem entsprechenden Wahlergebnis übereinstimmt.
Bei der Aggregation von Fragebögen handelt es sich um eine Technik, die mehrere Umfrageergebnisse zu einem bestimmten Thema oder einer bestimmten Wahl zusammenführt, um einen zuverlässigeren Einblick in den Zweck zu erhalten. Dies kann durch einfache Mittelung von Umfragen oder durch die Verwendung komplexer Systeme wie verschiedener Bayes’scher Modelle bei der Kombination von Umfragen, Glättungsalgorithmen oder statistischer Modellierung eines theoretischen Zeitreihenprozesses (der Umfragen hervorrufen soll) erfolgen. Wir können alle diese Methoden unter anderen Überschriften definieren und diskutieren, aber ob der geworfene Stein den verängstigten Frosch berührt, ist ein anderes Fragezeichen.
Durch die Berücksichtigung der Unterschiede im Design und der Stichprobengröße der verschiedenen Fragebögen kann die Anwendung der Fragebogenaggregation theoretisch den Gesamtspielraum für Unvollkommenheiten verringern und die Genauigkeit der Vorhersage erhöhen. Aber leider sind Probleme mit der Zugänglichkeit und Zuverlässigkeit relevanter Daten Herausforderungen, die in der Türkei nur einmal bewältigt werden können. In ihrer Masterarbeit untersuchte İrem Aydaş (2020) die Berichtspraktiken von 374 Vorwahlbefragungen aus 11 Wahlperioden in der Türkei Mitte 2011–2019 und deckte die auffällige Tatsache auf: Etwa 69 % aller dieser Umfragen wurden ohne Angabe von Gründen gemeldet die Stichprobenformel. [2] . Die mangelnde methodische Transparenz gefährdet die Aussagekraft dieser Umfragen. Umfragen, Stichprobenfehler [3] Darüber hinaus weist es auch Rahmen-, Mess- und Spezifikationsfehler auf, die bei gemeldeten Fehlern häufig vernachlässigt werden. Darüber hinaus trüben auch bestimmte Stichprobenmuster von Unternehmen, intransparente Attributionsformeln oder Tendenzen, die auf ihre politischen Zugehörigkeiten/Zugehörigkeiten zurückgeführt werden können.
Daher ist es nicht einfach, echte Veränderungen in der politischen Stimmung der Wählerschaft, nämlich der „öffentlichen Meinung“, von der möglichen Voreingenommenheit in den Meinungsumfragen zu unterscheiden. Das von uns vorgeschlagene System zur Aggregation von Umfragen wertet Vorwahlumfragen in der Türkei auf der Grundlage der bisherigen Leistung von Umfrageunternehmen aus und verwendet dabei ein von Martin et al. eingeführtes Maß für die Genauigkeit, ohne zu vergessen, dass dies passieren wird.
Daher fehlt einem Zufallsumfrage-Kombinationsverfahren (oder einer statistischen Modellierung erneuerter Umfragedaten), das sich nicht nur auf unterbewertete Umfragen beschränkt, die wissenschaftliche Grundlage, auf der es verteidigt werden kann. Die Prüfung einer großen Anzahl von Vorwahlumfragen auf der Grundlage ihrer „Genauigkeit“ anhand der von uns verwendeten Kriterien kann uns jedoch helfen zu verstehen, ob die für Umfrageunternehmen typischen Trends und/oder politischen Zugehörigkeiten echt sind. Anschließend wenden wir uns unserem Beispiel für die Zusammenführung von Umfragen zu, das auf der Annahme basiert, dass eine Umfrage umso mehr Aufwand bei der Zusammenführung verdient, je genauer sie ist.
Worüber wir jetzt sprechen, ist die mathematische Darstellung des Maßes für die Verzerrung einer Umfrage nach Martin et al. (2005) „ A“ Lass uns mit zeigen Mit diesem Maß lässt sich quantifizieren, wie genau eine Umfrage den Ausgang einer parteiübergreifenden Wahl annimmt. Unter F/Etatsächlicher Stimmenanteil bei der Wahl für Republikaner bzw. Demokraten und r/dist das Verstärkungsverhältnis für zwei Parteien in einer vernünftigen Wahlumfrage.
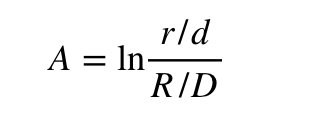
A Maß ist der natürliche Logarithmus des Verhältnisses dieser beiden Verhältnisse; vergleicht die in der Umfrage behauptete Wählerquote in der Mitte der Partei mit der tatsächlichen Stimmenquote. Stimmt das Umfrageergebnis vollständig mit dem Wahlergebnis überein, r/dmit F/Ewird gleich sein und A wird Null sein. Wenn bei der Umfrage festgestellt wurde, dass die Wählerquote der siegreichen Partei höher ist als das Wahlergebnis r/d, F/Ewird größer sein als und A wird positiv sein. Im Gegenteil, wenn die Umfrage ergab, dass die Wählerquote der siegreichen Partei niedriger ist als das Wahlergebnis r/d, F/Ewird kleiner sein als und A wird negativ sein. Deswegen, AMaß ist eine Methode zur Quantifizierung der Verzerrung (Bias) einer Umfrage. Je näher sie bei Null liegt, desto voreingenommener und erfolgreicher wird die Umfrage sein. [4].
Allerdings im brandneuen Zustand ADa es nur für Zweiparteiensysteme geeignet ist, haben Arzheimer und Evans (2014) dieses System verallgemeinert, indem sie es auf Mehrparteienwahlen mit mehr als zwei Parteien anwendbar gemacht haben, was wir als neues Kriterium bezeichnen werden – hier möchte ich gerne Leiten Sie den neugierigen Leser ohne weitere mathematische Details zu den relevanten Artikeln. Tabelle 1In sehen wir die Rangfolge der Wahlumfragen, die höchstens einen Monat vor der CB-Wahl 2018 durchgeführt wurden. Im Verhältnis zu ihrer durchschnittlichen Fehlerquote ist der Wert für eine Umfrage der Durchschnitt der absoluten Werte der auf Kandidaten basierenden Vermögenswerte ( d. h. die Tendenzen der Kandidaten) in der Tabelle, und je näher sie bei 0 liegt, desto näher bei 0 liegt die tatsächliche Wahlumfrage des betreffenden Unternehmens. zeigt, dass sie so gut mit dem Ergebnis übereinstimmt. Tabelle 2, Tabelle 1Es handelt sich um eine nach Datum sortierte Liste der Umfrageergebnisse in , einschließlich veröffentlichter Ergebnisse, deren Wert berechnet wird.
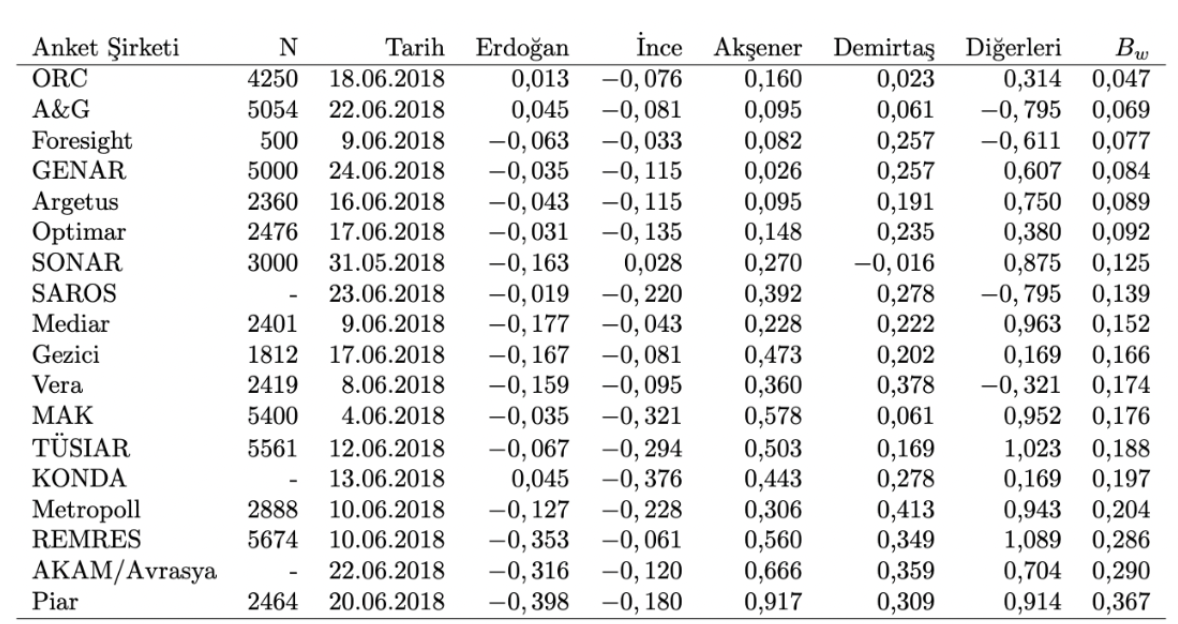
Tabelle 1
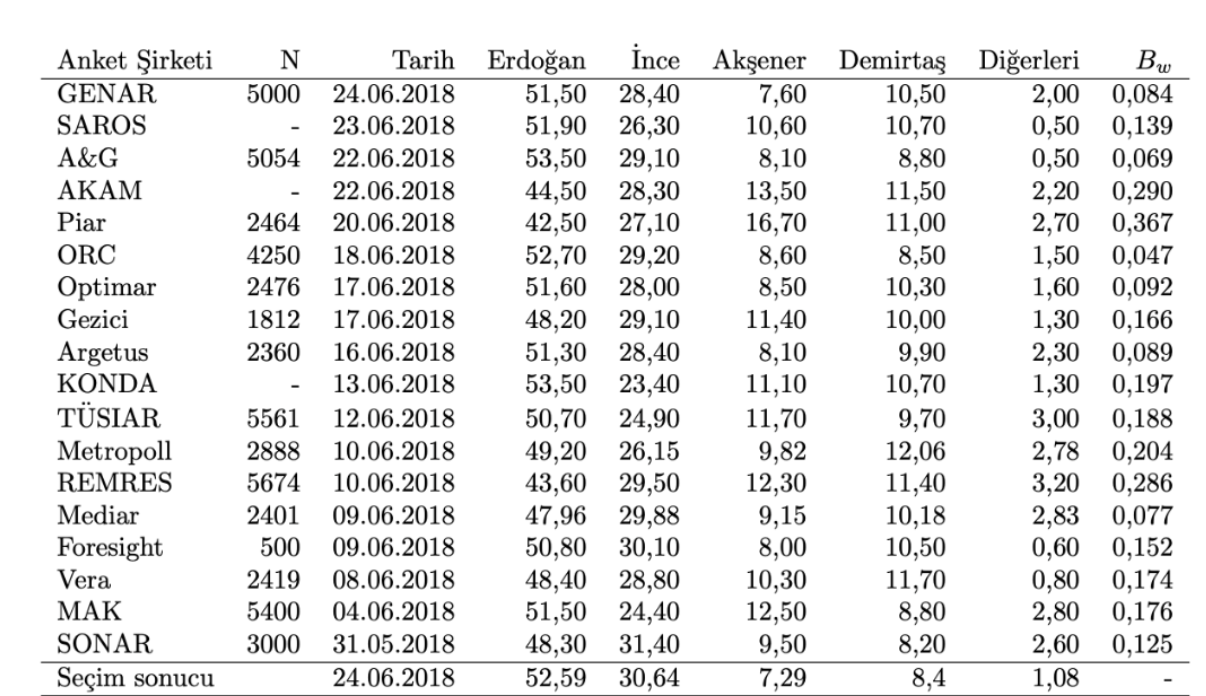
Tabelle 2
Indem wir die Leistung der Umfrageunternehmen bei den Kommunalwahlen 2019 (basierend auf der Benchmark) mit den Ergebnissen der Präsidentschaftswahlen 2018 kombinieren, berechnen wir die durchschnittliche Belastung der Umfrageunternehmen, die das Ergebnis für die bevorstehende CB-Wahl „teilen“, also dass wir ein Umfragekonsolidierungsdiagramm erstellen können, das nach den bisherigen Erfolgen der Unternehmen gewichtet ist.
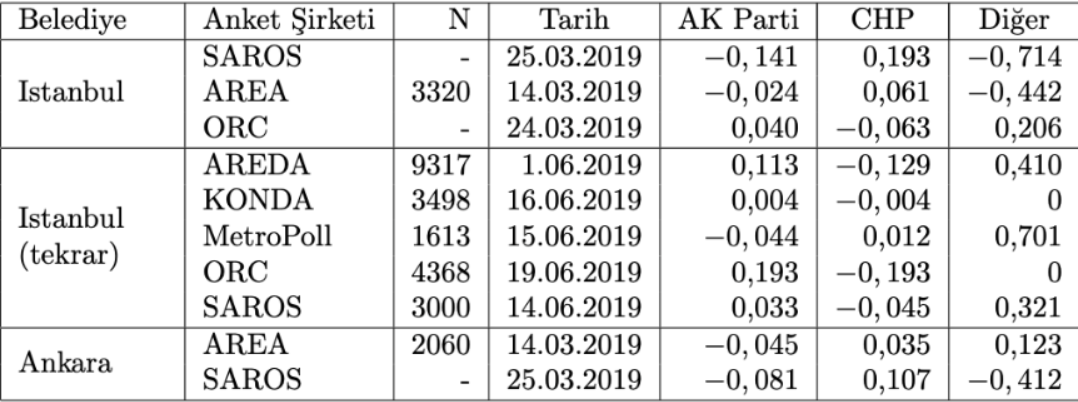
Tabelle 3: Trends nach Kandidaten für Umfrageunternehmen, die Ergebnisse von Kommunalwahlen bekannt gegeben haben.
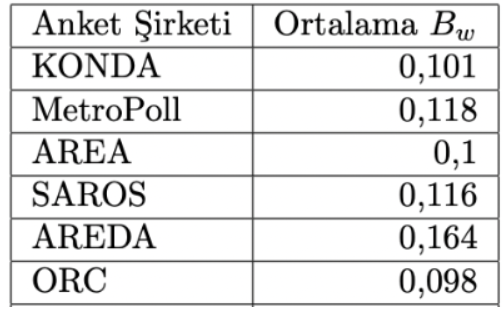
Tabelle 4: Durchschnittliches Bw im Vergleich zu den CB- und Kommunalwahlen 2018 Werte.
Wenn ein Umfrageunternehmen relativ neu ist, das heißt, es hat noch keine Messwerte für eine Auswahl, dann gewichten wir dieses Unternehmen (das wir auswählen werden) mit der Punktzahl des Unternehmens mit der niedrigsten Punktzahl unter den Unternehmen in der Teilmenge, sodass Es Nur Wir bestrafen nicht, weil es neu ist. Werfen wir abschließend einen Blick auf diese Idee in der Praxis.
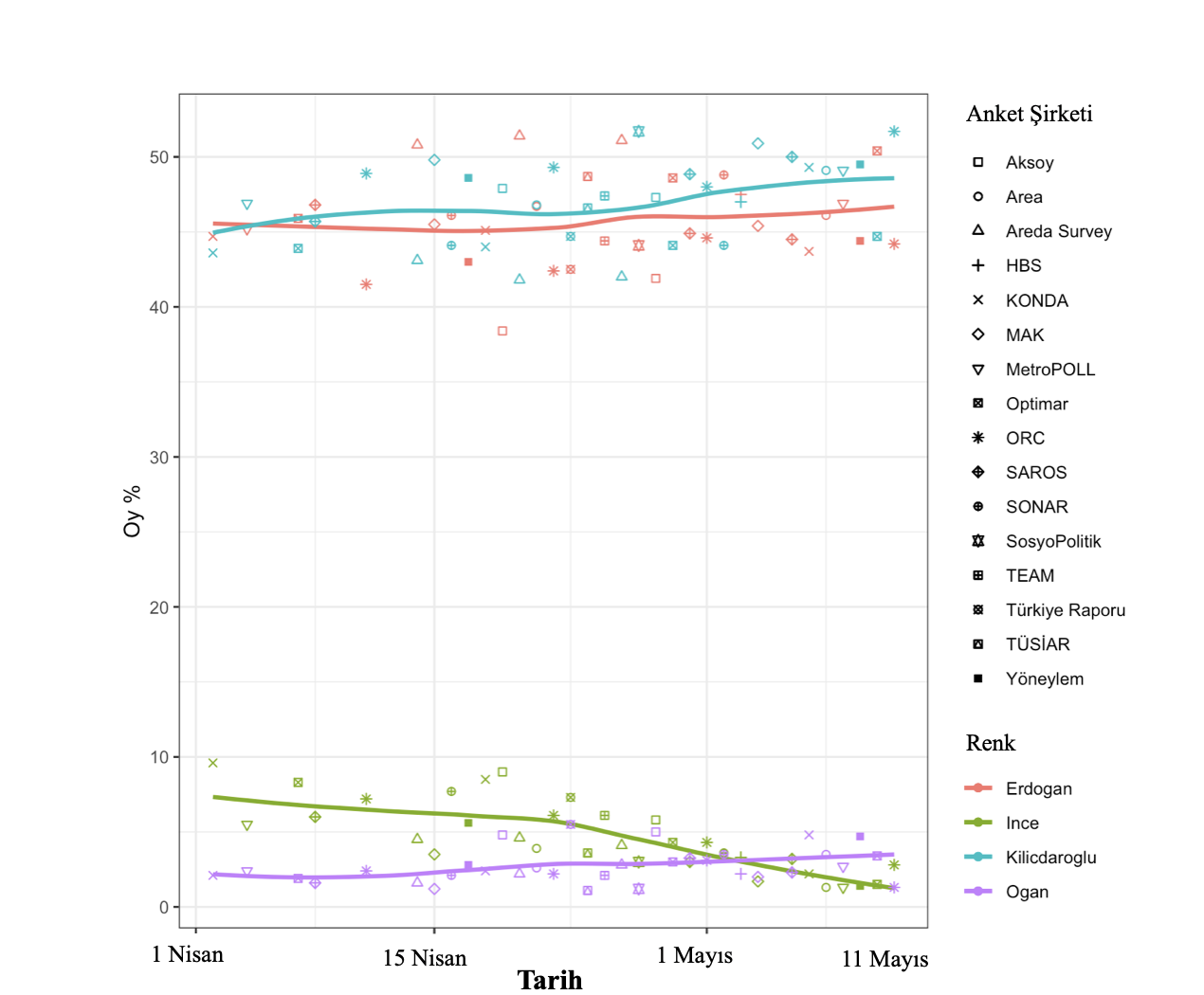
Im obigen Beispiel sehen wir ein Beispiel für eine Umfragezusammenführung, die die Wahlumfragen umfasst, die die börsennotierten Unternehmen zuletzt bis zum 12. Mai um 13:00 Uhr veröffentlicht haben. [5] . Die Ergebnisse der beiden jüngsten Umfragen, die dieser Zusammenführung hinzugefügt wurden, sind eine Überlegung wert; einer von Optimar, einer vom gefräßigen ORC: beides in fast der gleichen Zeitspanne [6]In den von den Geschäftsführern beider Umfragen geteilten Berichten heißt es, dass die Umfragen eine Fehlerquote von 1,8 im 95-Prozent-Glaubensbereich aufweisen, und beide Umfragen behaupten, dass sie die Wählerpopulation repräsentieren.
Daher ist die Situation, mit der wir konfrontiert sind, den widersprüchlichen Umfrageergebnissen, die ich im vorherigen Artikel beschrieben habe, sehr ähnlich, und wir wissen, dass mindestens eines dieser beiden Ergebnisse sehr(!) höchstwahrscheinlich entweder extrem falsch oder voreingenommen ist … Wir Wir werden Optimars nicht einbeziehen. Wenn wir also alles andere konstant halten, würde die folgende Grafik erscheinen. Bei der letzten Zusammenführung halten wir den Optimar, extrahieren den ORC und zeichnen entsprechend. Welche dieser Grafiken der Realität besser entspricht, erfahren wir morgen.
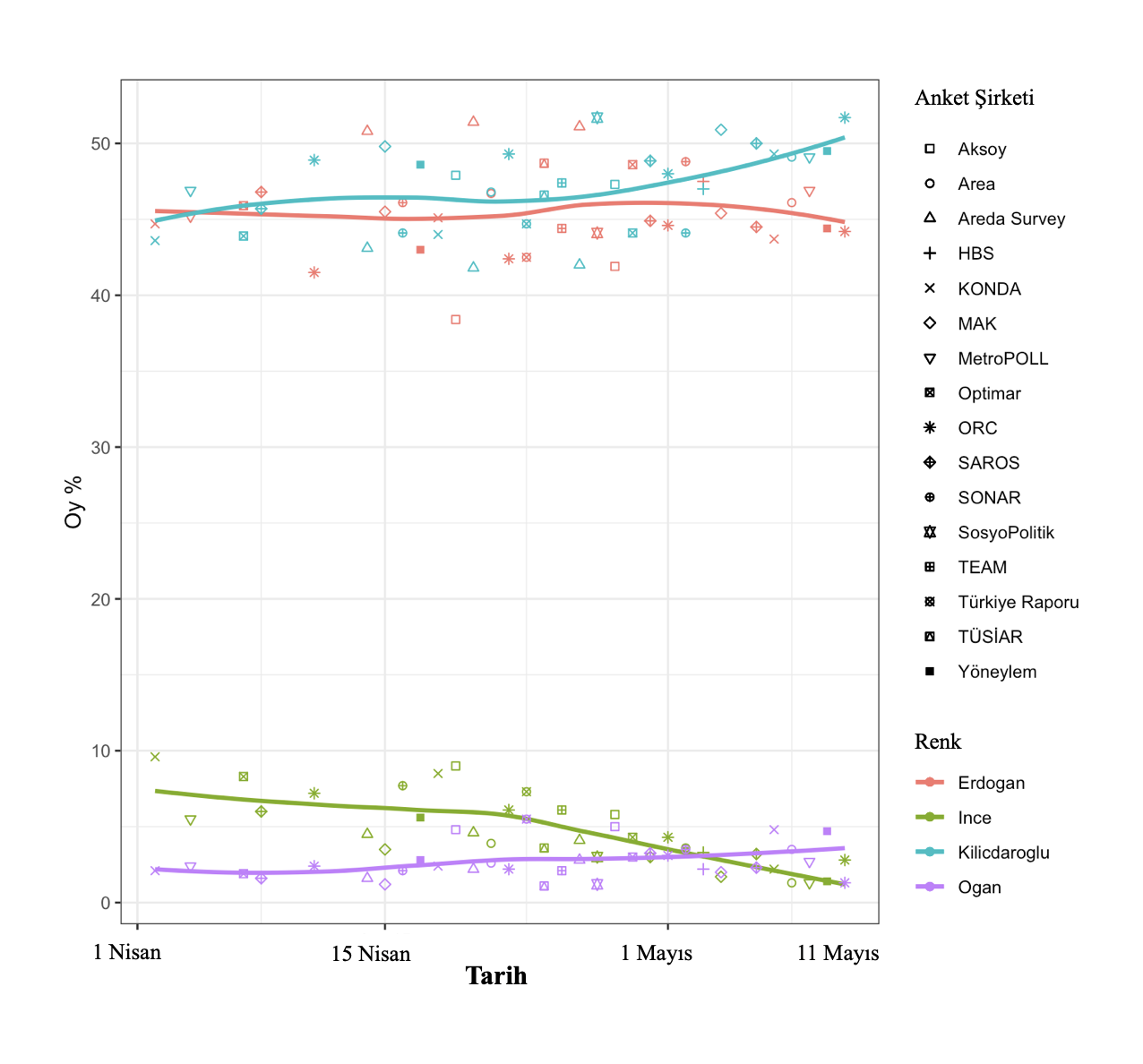
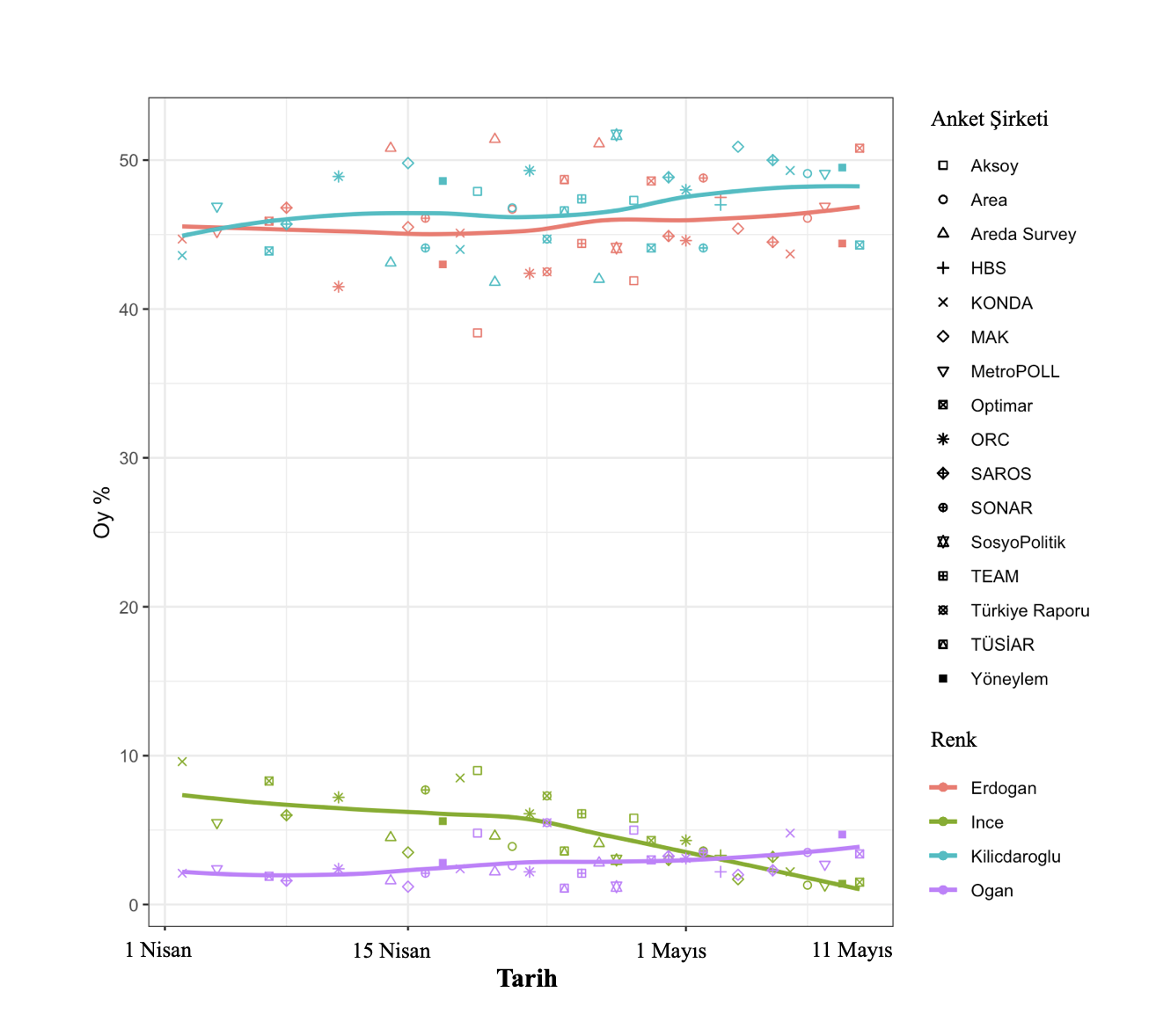
* Oguz Guerk, Er studierte Mathematik und Wirtschaftswissenschaften an der Boğaziçi-Universität. Methodik (qualitativ, quantitativ, rechnerisch) steht im Vordergrund seiner Interessen- und Arbeitsgebiete. Politus ERC-Projekt am Koç University Center for Computational Social Sciences. Analytik(https://politusanalytics.com/) arbeitet als Forscher an der Erstellung einer Datenplattform.
[1] Der vorherige Artikel wurde tatsächlich nach der ersten Version dieses Artikels geschrieben. Die Notwendigkeit, die dem vorherigen Artikel zugrunde lag, bestand darin, zu verstehen, wie es möglich ist, dass die Umfrageergebnisse verschiedener Unternehmen in dem Anspruch, die Bevölkerung zu repräsentieren, voneinander abweichen – fast bis zum Punkt des Widerspruchs. Dazu habe ich zwei fiktive Umfrageergebnisse für die bevorstehende CB-Wahl mit einem statistischen „Spielzeugmodell“ verglichen: „Inwieweit können wir der öffentlichen Meinung oder Meinungsumfragen vertrauen?“, T24 (9. Mai 2023), https:// t24.com.tr/news/public Opinion-Wessen-Stimme-oder-in welchem Umfang-können wir öffentlichen Meinungsumfragen vertrauen,1108414.
[2]İrem Aydaş, Vorwahlumfragen in der Türkei, unveröffentlichte Masterarbeit, Sabancı-Universität, 2020.
[3] Im Allgemeinen liefern Umfragen mit großen Stichproben – unter sonst gleichen Bedingungen – genauere Ergebnisse als Umfragen mit kleinen Stichproben, da eine größere Stichprobe eine geringere Fehlerquote zulässt; Das bedeutet, dass die Ergebnisse repräsentativer für die untersuchte Population sind. Im Gegensatz zu Stichprobenfehlern können stichprobenunabhängige Fehler jedoch nicht einfach dadurch reduziert werden, dass mehr und größere Umfragen durchgeführt werden. Vergessen wir nicht, dass die Imperfektion ein statistisches Konzept ist, mit dem der Grad der Unsicherheit in einer Stichprobenschätzung angegeben wird, der auf der Annahme basiert, dass die Stichprobe zufällig generiert wird. Wenn die Stichprobe nicht zufällig generiert wurde, ist die Fehlerspanne kein gültiges Maß für die mit der jeweiligen Schätzung verbundene Unsicherheit, und die Angabe der Fehlerspanne wäre dann irreführend – darunter leiden leider auch viele Umfragen in der Türkei. Daher ist es von unschätzbarem Wert, die Grenzen der Probe und des Systems zu kennen, mit dem sie erstellt wurde.
[4] Der Nutzen dieser Kennzahl ergibt sich auch aus der Tatsache, dass sie schnell berechnet und zusammengefasst werden kann; In dem Artikel diskutieren Martin et al. (2005), warum Umfragen früheren Methoden zur Messung der Genauigkeit überlegen sind: Elizabeth A. Martin, Michael W. Traugott und Courtney Kennedy, A review and Proposal for a newmeasure of poll precision, The Public Opinion Quarterly, 69(3):342–369, 2005. Dieses Kriterium kann als abhängige Variable in multivariaten statistischen Analysen über die Art und das Ausmaß von Trends verwendet werden, die sich auf Auswahlannahmen auswirken, und kann dabei helfen, mögliche Quellen dieser Trends zu identifizieren. Vergleichbar ist es in der Mitte von Umfragen, die sich bei verschiedenen Wahlen und in der Zahl der Unentschlossenen bzw. dem Umgang mit Unentschlossenen unterscheiden. Für weitere Einzelheiten und Erläuterungen: Kai Arzheimer und Jocelyn Evans, A new multinomial Accuracy Measure for Polling Bias, Political Analysis, 22(1):31–44, 2014.
[5]Einzelheiten finden Sie im Bericht von Politus Analytics, an dem ich als Forscher beteiligt bin: https://politusanalytics.com/wp-content/uploads/2023/05/Politus-Turkiye-Panoramasi-1.pdf
[6]Es wird angegeben, dass Optimar die entsprechende Umfrage Mitte des 9. und 11. Mai durchgeführt hat, während ORC sie Mitte des 10. und 11. Mai durchgeführt hat.
T24